AI를 활용한 백엔드 개발 4단계 워크플로우
AI가 코드도 작성해주는 시대가 온 지금, AI가 작성한 코드를 얼마나 잘 검사하고 통제하느냐에서 결정된다고 생각한다. 이를 위해서 명령 프롬프트나 여러 기술들을 잘 사용하는 것도 중요하지만, 프로젝트 전체의 주도권을 유지할 수 있도록 워크플로우를 설계하는 것이 가장 중요하다고 생각한다.
AI는 매우 빠르게 코드를 작성하고 작업을 수행하지만, 그만큼 주변 시스템을 빠르게 망가뜨리게 되고, 어느 지점부터 문제가 생겼는지 추적하기 어려워질 수 있다.
4단계 워크플로우
Section titled “4단계 워크플로우”1단계. 프로젝트 분석
Section titled “1단계. 프로젝트 분석”AI에게 구현을 시키기 전, 작업을 하고자 하는 해당 프로젝트의 코드베이스를 학습시키는 단계다.
- 프롬프트 키워드: ‘깊이’, ‘매우 상세히’ 등의 키워드를 사용하여 코드베이스를 실제로 깊게 분석하도록 유도
- 파일 작성: 레이어 구조, 도메인 용어, 기존 컴포넌트 명칭 등을 CLAUDE.md 혹은 별도의 분석 문서에 기록(AI가 세션이 바뀌어도 컨텍스트를 유지할 수 있도록)
2단계. 새로 개발할 내용에 대한 스펙
Section titled “2단계. 새로 개발할 내용에 대한 스펙”구현 전, AI가 새로 개발할 기능에 대한 스펙을 작성하는 단계다.
- 범위 정의: 어떤 기능을 만들지를 명확히 정의하여, 방향성 및 구현 범위를 좁혀 AI가 임의로 범위를 확장하는 것을 방지
- 환각 방지: 요구사항이 모호하면 AI는 환각(Hallucination)으로 빈틈을 채울 수 있기 때문에 무엇을 만들지를 명확히 정의하며 계속해서 AI와 질의하며 목표 고도화
3단계. 계획
Section titled “3단계. 계획”AI가 목표 달성을 위해 어떤 단계를 거쳐야 하는지 작성하는 단계다.
- 마일스톤과 세부 작업으로 쪼개어 작성: 큰 목표를 달성하기 위해 필요한 단계들을 마일스톤과 세부 작업으로 쪼개어 작성
- 검토 및 피드백: AI가 작성한 계획을 검토하며, AI가 놓칠 수 있는 기술적 디테일이나 백엔드 시스템의 특성을 보완하여 계획을 고도화
- 파일 기록: 계획을 별도의 파일로 기록하여, AI가 세션이 바뀌거나 컨텍스트가 초기화되어도 계획을 참조하여 중간에 작업을 이어갈 수 있도록 함
4단계. 구현
Section titled “4단계. 구현”AI에게 단계별로 구현을 시킨 뒤 감독하는 단계다.
- 명령: Agent, Skills 혹은 상세한 프롬프트를 활용하여 구현 지시
- 롤백: 방향이 틀어지면 점진적 수정 대신 —
git reset이나revert로 되돌린 후 범위 재설정 및 다시 구현 지시
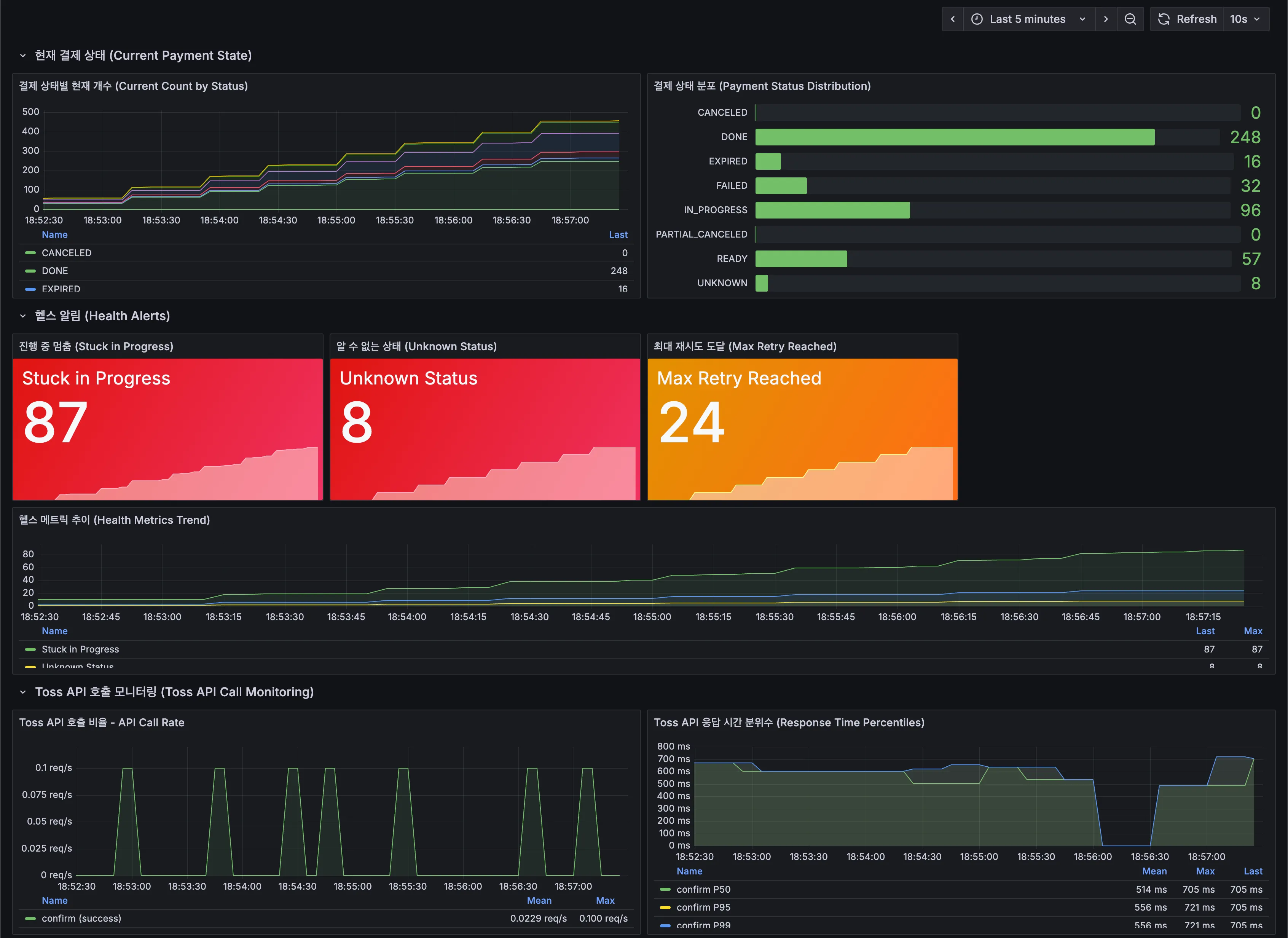
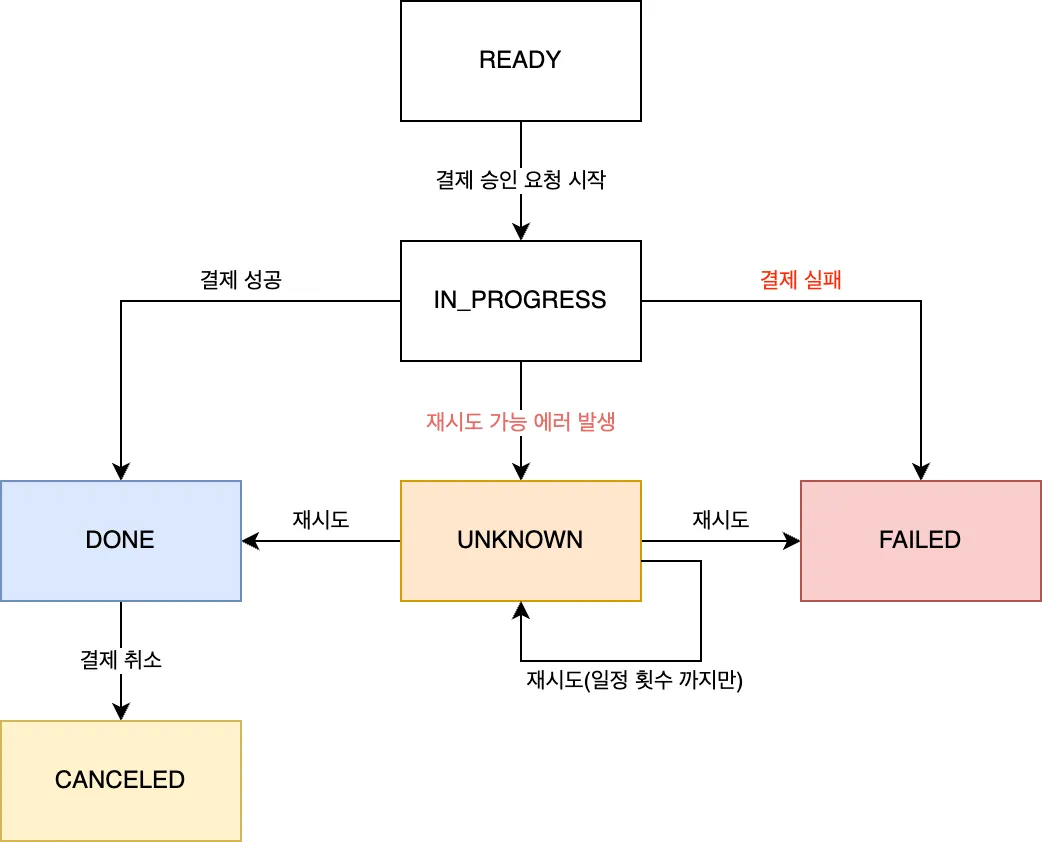
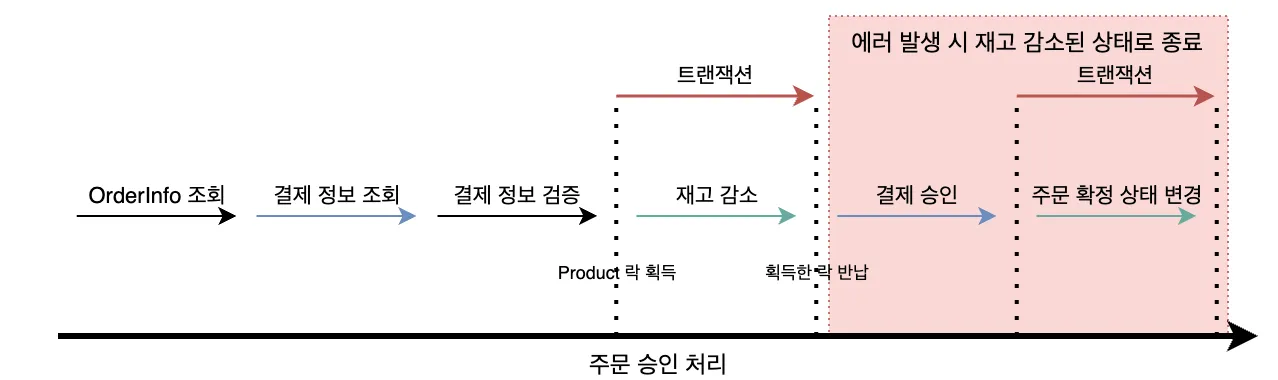
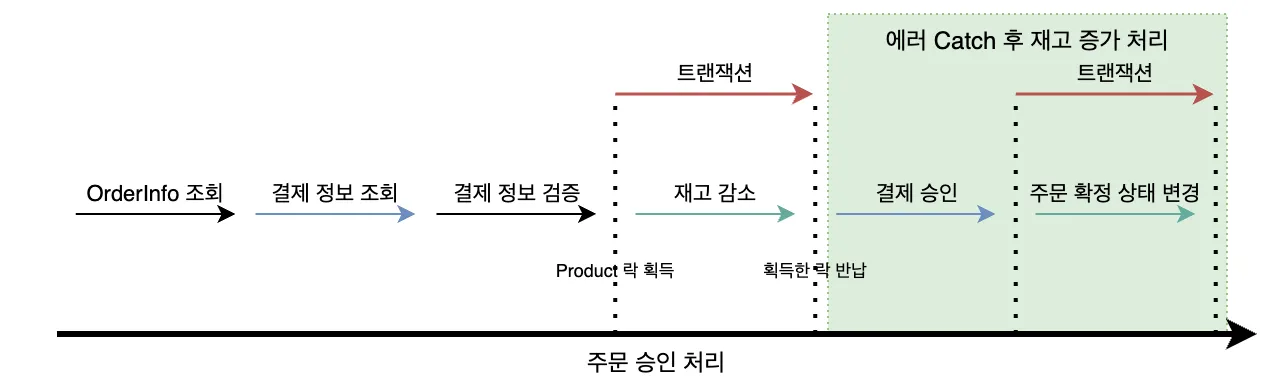
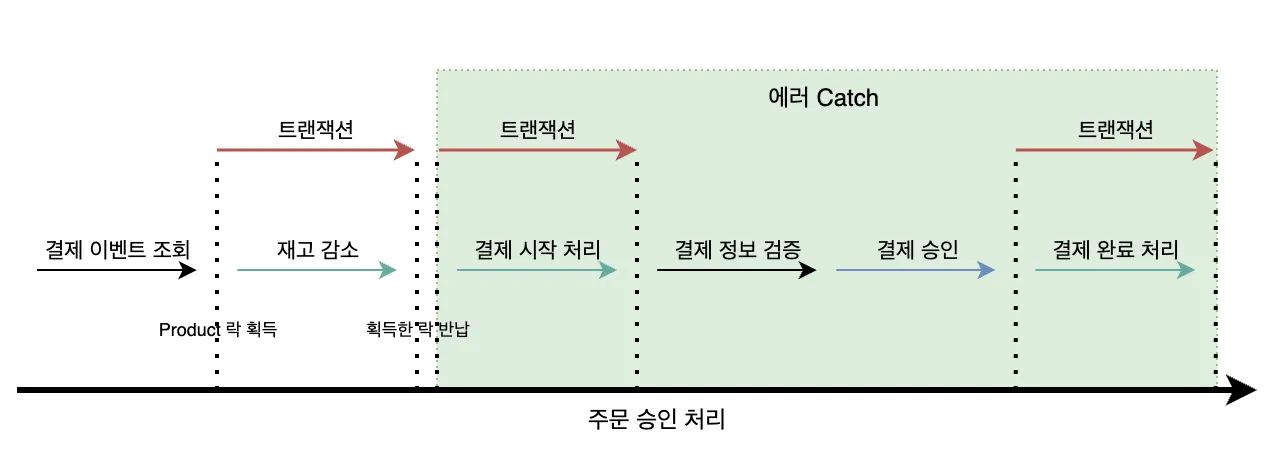
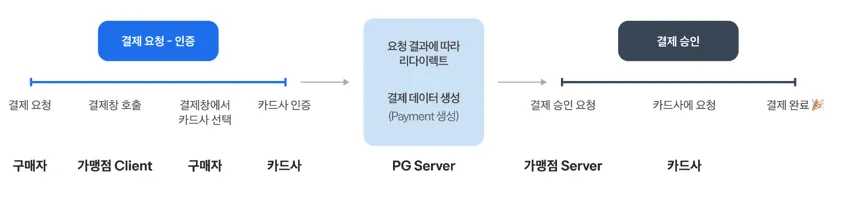
결제 시스템의 새로운 기능을 개발하면서, AI를 활용하여 트랜잭션 설계와 구현을 진행했다. 구현된 기술적 내용은 보상 트랜잭션 실패 상황 극복 가능한 결제 플로우 설계에서 자세히 다룬다.
1. 프로젝트 분석
Section titled “1. 프로젝트 분석”SPEC 작성에 앞서, 프로젝트의 기본 정보를 CLAUDE.md 파일에 정리했다.
- 자체 분석: AI에게 프로젝트의 레이어 구조, 도메인 용어, 기존 컴포넌트 이름 등을 분석하게 하고, 그 결과를 CLAUDE.md에 작성하도록 지시
- 추가 정보 제공: AI가 분석한 내용을 확인한 뒤, 추가로 알고 있는 세부 사항이나 기술적 디테일을 CLAUDE.md에 보완하여 작성
- 행동 지침 설정: 코드 작성 시 지켜야 할 제약사항이나 작업 진행 방식에 대한 지침을 CLAUDE.md에 명시하여, 불필요한 변경이나 AI가 자체 판단으로 구현을 시작하는 것을 방지
작업 진행 방식은 아래와 같이 작업 진행 방식, 참조해야 할 파일, 구현 시 지켜야 할 제약사항 등을 명시했다.
// ... (프로젝트 분석 내용 생략) ...
## Development Workflow
Follow this required workflow when implementing tasks:
1. Review Specifications: Always refer to `TECHSPEC.md` to understand the technical requirements before starting implementation.2. Follow the Plan: Use `PLAN.md` as the authoritative source for the implementation sequence. * After completing a task, mark it as checked in `PLAN.md`. * Always begin work on the next unchecked task listed in `PLAN.md`.3. Test-First Development: * Write tests (unit or integration) *before* writing the implementation code. * Implement the minimum amount of code necessary to pass the newly written tests. Avoid making overly large or unrelated changes.4. Update Documentation: * Upon task completion, if the changes necessitate updates to guidance or specification files (e.g., CLAUDE.md, TECHSPEC.md), update those files accordingly.
// ... (추가 분석 내용 생략) ...2. 목표 설계
Section titled “2. 목표 설계”AI에게 구현을 시키기 전에, 새로 개발할 기능에 대한 스펙을 TECHSPEC.md 파일에 작성했다.
- 초안 작성: AI에게 기능의 목적과 요구사항을 설명하여 초안을 작성하게 함
- 환각 방지: 초안이 모호하거나 불충분한 경우, AI와 계속해서 질의를 하면서 스펙을 고도화하여, AI가 환각으로 빈틈을 채우는 것을 방지
- 최종 스펙: 기능의 목적, 핵심 변경 사항, 상세 구현 내역 등을 포함하는 최종 스펙 문서 작성
### 1. 배경 및 목적
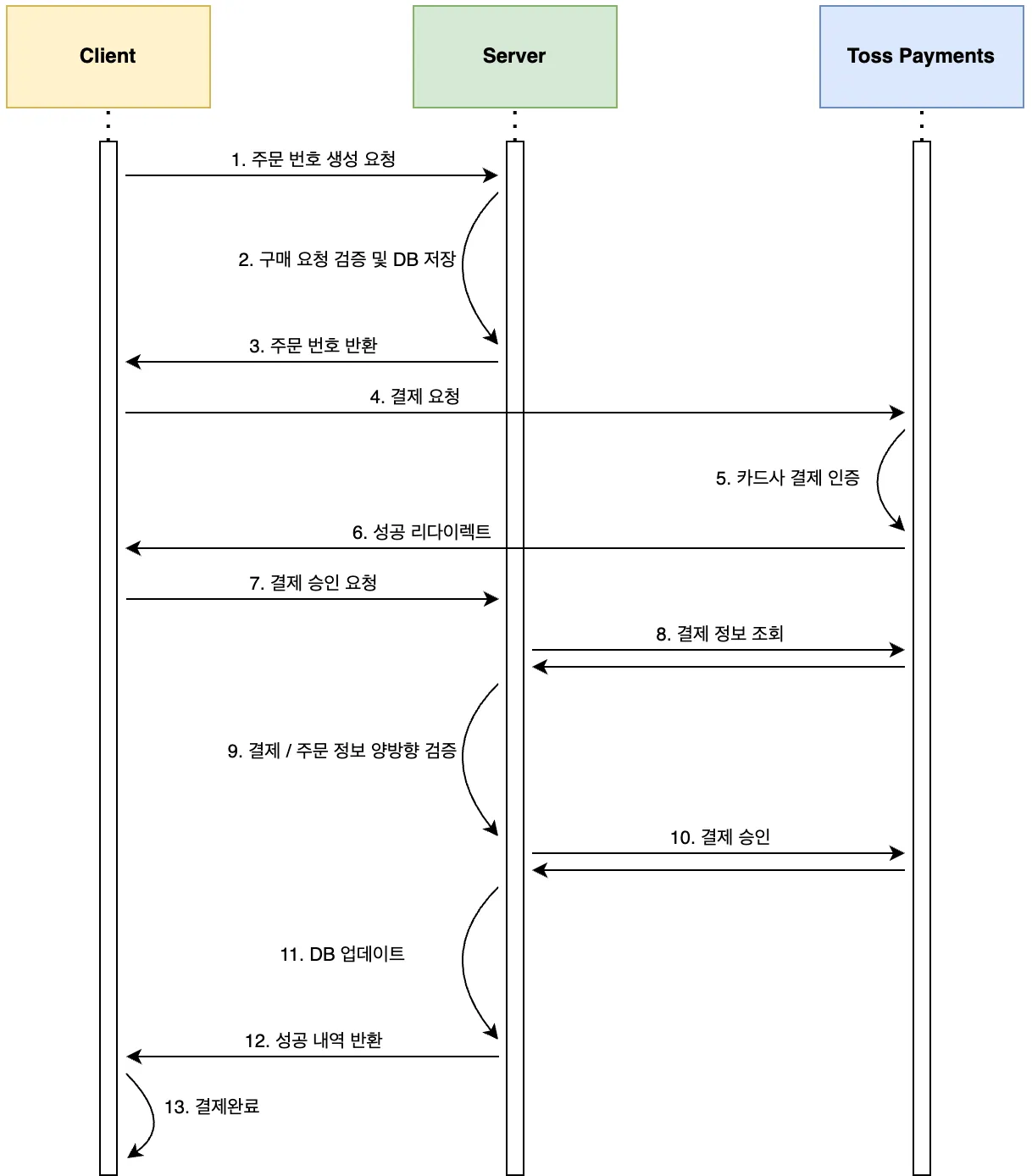
현재 결제 프로세스는 '재고 차감'과 '외부 PG 결제'가 순차적으로 진행됩니다. 만약 1단계(재고 차감) 성공 후 2단계(PG 결제)를 처리하는 도중 서버가 다운되면, ...
### 2. 핵심 변경 사항: 3단계 프로세스 도입
사용자 결제 요청의 전체 흐름을 3단계로 분리하여 구현합니다.
- 1단계 (Tx 1): 재고 차감 + 작업 생성 (단일 트랜잭션)- 2단계 (Non-Tx): 외부 PG사 결제 요청 (장애 위험 구간)- 3단계 (Tx 2): 결제 결과 반영 + 작업 상태 완료 (단일 트랜잭션)
### 3. 상세 구현 내역
### 3-1. [신규] '결제 프로세스 테이블' 스키마 정의
...(세부 스키마 정의 생략)...
### 3-2. [수정] 기존 결제 서비스 로직 변경
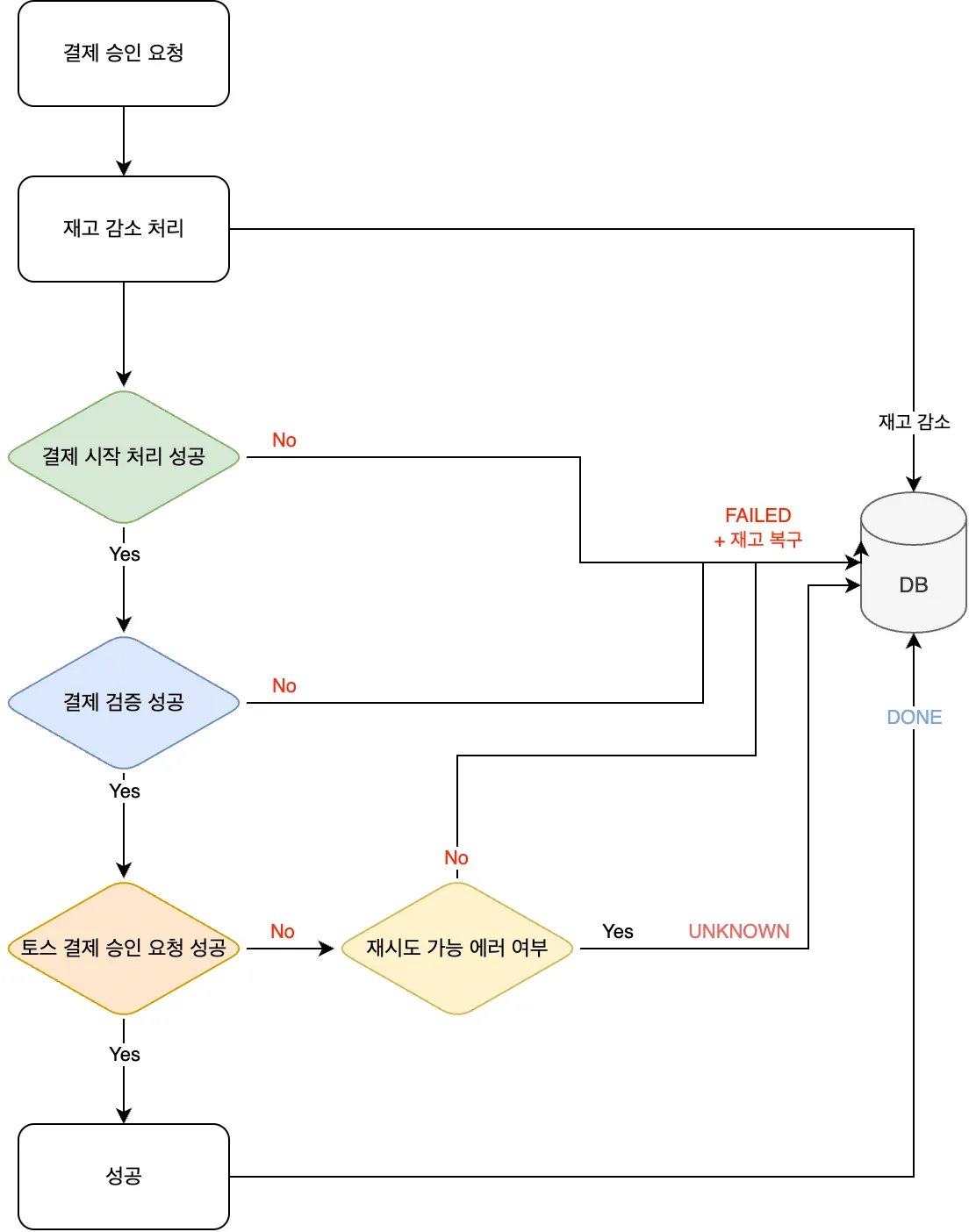
기존의 단일 결제 로직을 아래와 같이 3단계로 명확히 분리하고, 각 단계별 트랜잭션을 적용합니다.
1단계: 작업 생성 및 재고 차감 (Tx 1 - @Transactional)
- @Transactional 어노테이션 등으로 단일 트랜잭션을 보장합니다.- 로직 1: `payment_process` 테이블에 해당 `[주문_FK]`와 함께 'PROCESSING' 상태로 신규 작업을 INSERT 합니다.- 로직 2: 기존 로직대로 `[재고_테이블]`의 실제 재고를 차감하는 UPDATE를 실행합니다.- 이 트랜잭션이 성공적으로 커밋되어야만 다음 단계로 진행합니다. 실패 시(재고 부족 등) 모든 변경 사항이 롤백됩니다.
2단계: 외부 PG사 결제 처리 (Non-Tx)
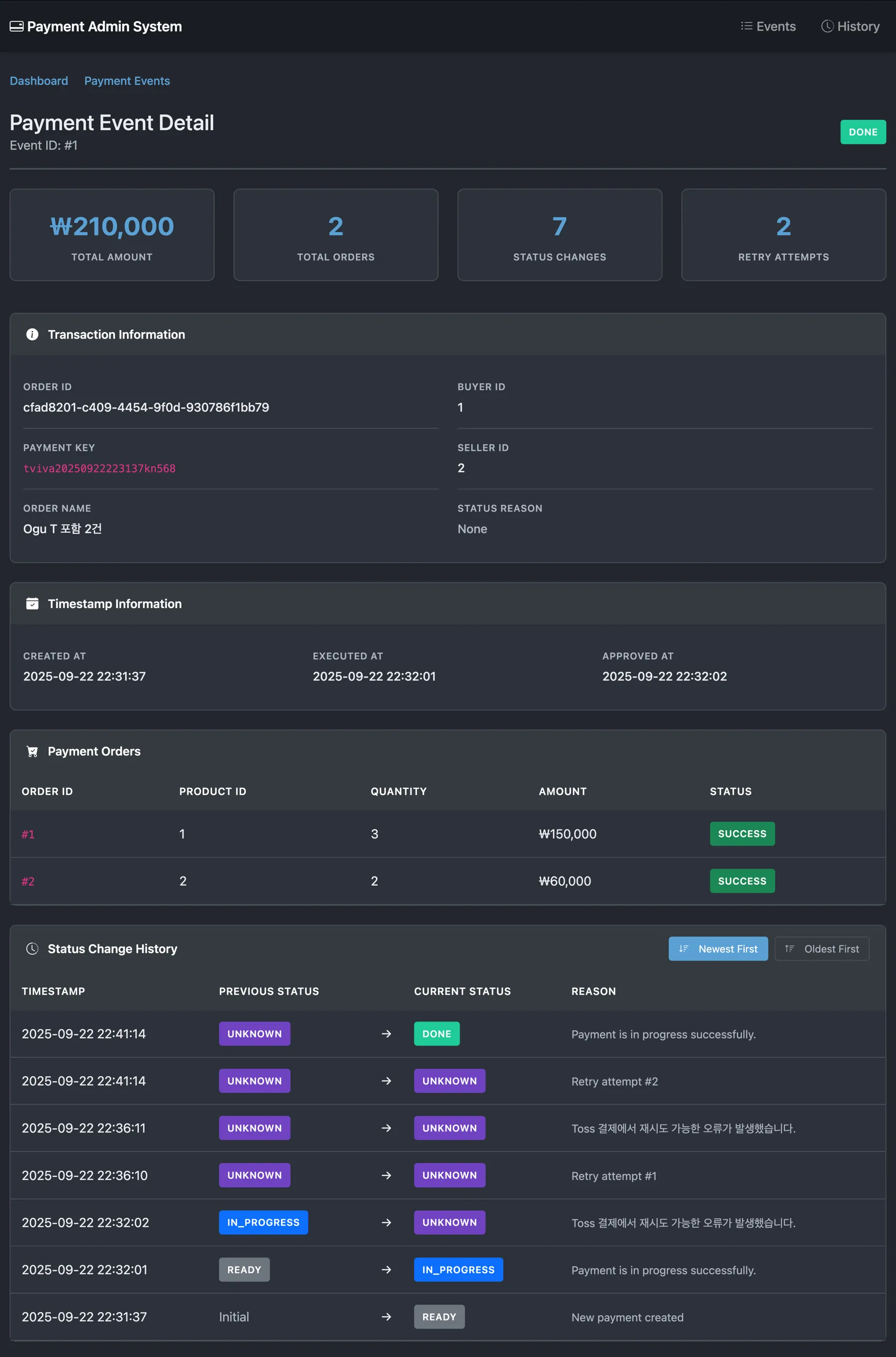
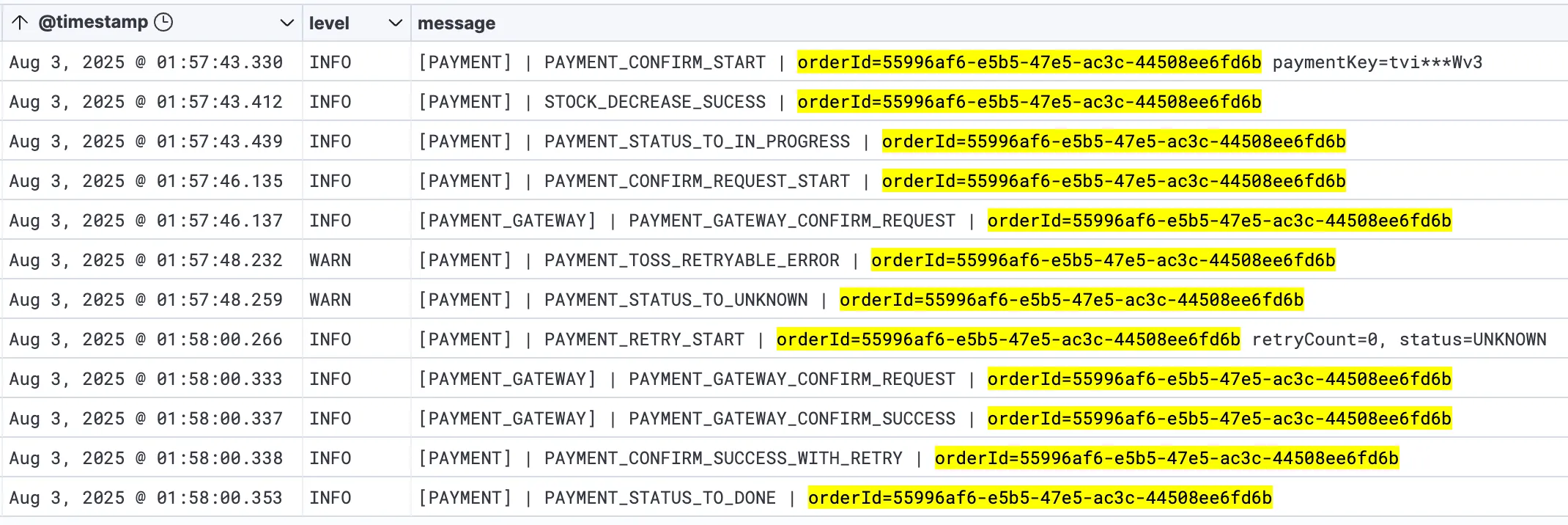
- 1단계 트랜잭션이 성공적으로 커밋된 후, 별도의 트랜잭션 없이 외부 PG사 결제 API를 호출합니다.- 이 단계에서 서버가 다운될 경우, `payment_process` 테이블에는 'PROCESSING' 상태의 작업이 남게 되며, 이것이 복구 대상이 됩니다.
3단계: 작업 완료 및 주문 상태 변경 (Tx 2 - @Transactional)
- PG사로부터 받은 결제 결과를 바탕으로 @Transactional이 적용된 별도의 메서드를 호출합니다.- [결제 성공 시] - 로직 1: `payment_process` 테이블에서 해당 작업의 상태를 'COMPLETED'로 UPDATE 합니다. - 로직 2: 기존 로직대로 `[주문_테이블]`의 상태를 '결제 완료'로 변경합니다.- [결제 실패 시] - 로직 1: `payment_process` 테이블에서 해당 작업의 상태를 'FAILED'로 UPDATE 합니다. - 로직 2 (보상 트랜잭션): 1단계에서 차감했던 재고를 다시 복구(증가)하는 UPDATE를 `[재고_테이블]`에 실행합니다. - 로직 3: `[주문_테이블]`의 상태를 '결제 실패' 등으로 변경합니다.
... (세부 구현 내역 생략) ...플랜 단계에서 마일스톤을 쪼개고, AI에게 구현 가이드를 작성하도록 지시한 뒤, AI가 놓칠 수 있는 백엔드의 세부 사항을 보완했다.
## Milestone 3: 장애 복구 로직 구현 (다음 작업)
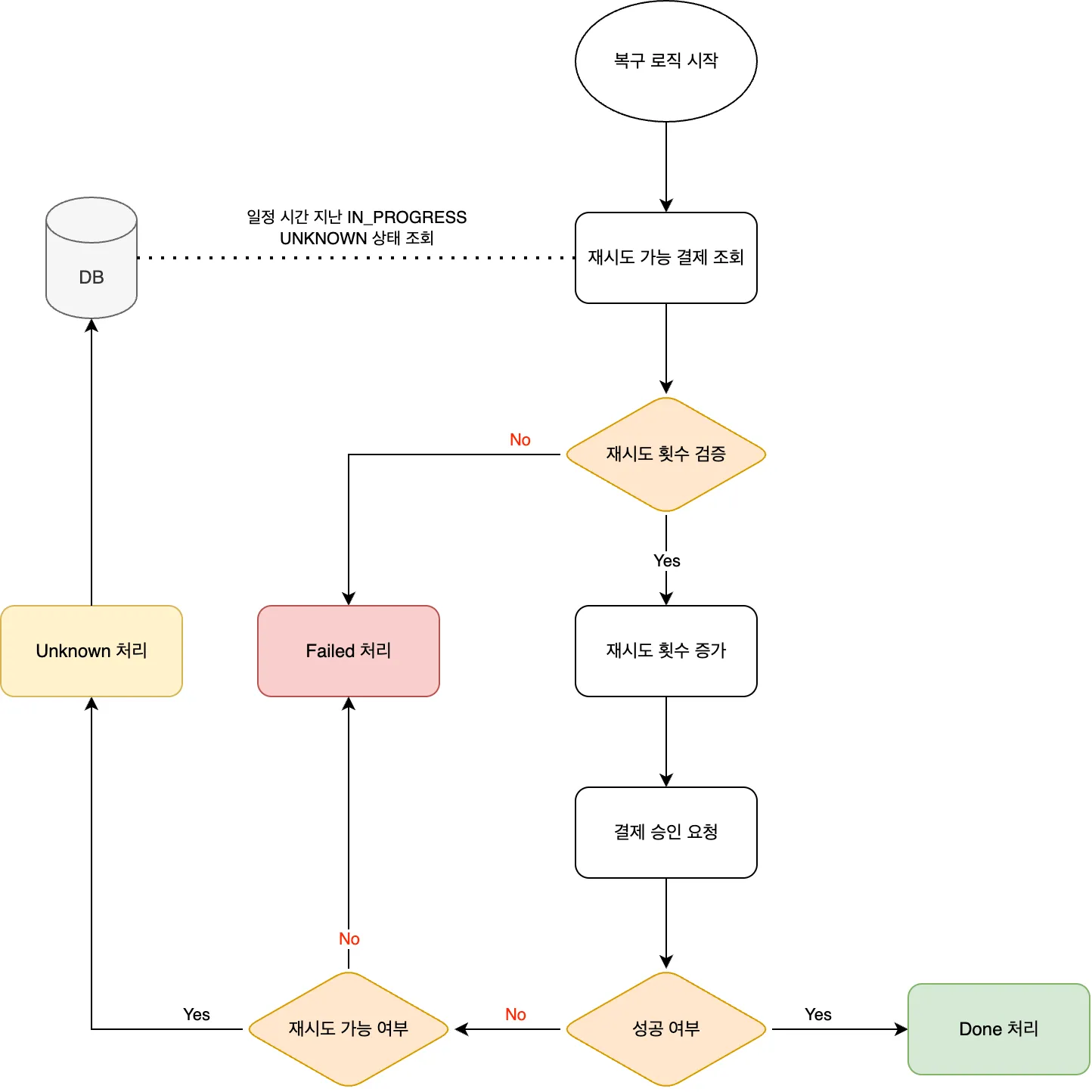
목표: 1단계와 3단계 사이, 즉 2단계(외부 결제) 도중 장애로 인해 'PROCESSING' 상태로 남겨진 작업을 찾아내어 상태를 동기화합니다.
### 구현 가이드
- [ ] Subtask 3.1: Toss API 결제 상태 조회 기능 확인 및 구현 - 목적: PROCESSING 상태 작업의 실제 결제 결과를 확인하기 위함 - 구현 위치: `TossOperator` 또는 새로운 UseCase - 필요 기능: - 메서드명 예시: `getPaymentStatus(String orderId)` 또는 `retrievePaymentInfo(String orderId)` - 반환 타입: Toss API 응답을 매핑한 DTO (예: `TossPaymentStatus`) - 필요한 정보: 결제 상태 (DONE, CANCELED, ABORTED 등), approvedAt, 실패 사유 - 참고: 기존 `TossOperator`에 해당 메서드가 있는지 먼저 확인 - Toss API 문서: [https://docs.tosspayments.com/reference#결제-조회](https://docs.tosspayments.com/reference#%EA%B2%B0%EC%A0%9C-%EC%A1%B0%ED%9A%8C)- [ ] Subtask 3.2: 복구 전용 UseCase 구현 - 파일 위치: `payment/application/usecase/PaymentRecoveryUseCase.java` - 의존성: - `PaymentProcessUseCase`: PROCESSING 작업 조회 - `PaymentLoadUseCase`: PaymentEvent 로드 - `PaymentTransactionCoordinator`: 복구 트랜잭션 실행 - `TossOperator` (또는 Toss 조회 UseCase): 실제 결제 상태 조회 - 핵심 메서드: `recoverStuckPayments()`
... (세부 구현 가이드 생략) ...그리고 작업이 완료되면, AI는 구현이 완료된 작업을 PLAN.md에 체크 표시하며, 다음 작업으로 넘어갈 수 있도록 했다.
## Milestone 3: 장애 복구 로직 구현 ✅ (완료)
목표: 1단계와 3단계 사이, 즉 2단계(외부 결제) 도중 장애로 인해 'PROCESSING' 상태로 남겨진 작업을 찾아내어 상태를 동기화합니다.
### 완료된 작업 요약
- [x] Subtask 3.1: Toss API 결제 상태 조회 기능 확인 ✅ - 기존 `TossOperator.findPaymentInfoByOrderId(String orderId)` 메서드 확인 - `TossPaymentInfo` 반환: 결제 상태, approvedAt, 모든 필요한 정보 포함 - 추가 구현 불필요- [x] Subtask 3.2: `PaymentRecoveryUseCase` 구현 ✅ - 파일 위치: `payment/application/usecase/PaymentRecoveryUseCase.java:65-116` - 핵심 메서드: - `recoverStuckPayments()`: PROCESSING 작업들을 순회하며 복구 - `recoverSinglePayment()`: 개별 결제 복구 로직 - 구현 특징: - 에러 격리: 한 작업 실패가 다른 작업에 영향 없음 - Toss 상태별 분기: DONE → success completion, 기타 → failure compensation - 구조화된 로깅: `EventType` 상수 활용- [x] Subtask 3.3: 스케줄러 통합 ✅ - `PaymentRecoverService` 인터페이스에 `recoverStuckPayments()` 추가 - `PaymentRecoverServiceImpl` 구현 완료 - `PaymentScheduler` 스케줄링 메서드 추가: - `@Scheduled(fixedDelayString = "${scheduler.payment-recovery.interval-ms:60000}")` - 60초마다 자동 실행4. 구현 진행
Section titled “4. 구현 진행”PLAN은 고정된 문서로 하는 것이 아니라, 작업이 완료될 때마다 검토하고 피드백을 반영하여 업데이트하는 방식으로 진행했다.
- 최소 하나의 서브 테스크 - 최대 하나의 마일스톤만 작업을 진행하도록 하고, 작업 범위를 특정하여 AI가 임의로 작업 범위를 확장하는 것을 방지
- 컨텍스트 윈도우가 가득 차거나 세션이 바뀌어도, PLAN 파일을 참조하여 작업의 진행 상황과 다음 단계에 대한 정보를 유지할 수 있도록 함
- 중도에 PLAN 파일에 추가적인 메모나 피드백을 직접 작성하여, AI가 이를 반영하여 작업을 수행하도록 지시
또한, 이 파일을 작성함으로써, AI 뿐만 아니라 개발자 자신도 전체 작업의 흐름과 세부 사항을 명확히 파악할 수 있게 되어, 기술적 디테일을 보완하는 데 큰 도움이 되었다.
회고 및 결론
Section titled “회고 및 결론”이번 작업은 4단계 워크플로우를 실제 결제 시스템 개발에 적용했고, 다음과 같은 성과를 얻을 수 있었다.
- 방향 유지: AI가 임의로 작업 범위를 확장할 때 PLAN을 기준으로 즉시 재설정 가능
- 세션 연속성: 컨텍스트 윈도우가 초기화되어도 PLAN 파일로 작업 흐름 유지
- 요구 사항 고도화: PLAN 검토 과정에서 요구사항이 모호하거나 불충분한 부분을 발견하여, AI와 질의하며 고도화할 수 있는 기회 확보
다만 돌아보면 아쉬운 지점도 있다.
Skills 활용
Section titled “Skills 활용”이번 프로젝트에서 마일스톤 구현 지시, 코드 검토 요청, PLAN 업데이트, 테스트 실행 확인 등 반복되는 패턴이 매 마일스톤마다 거의 동일한 순서로 반복됐다.
스킬 파일 구성
Section titled “스킬 파일 구성”스킬 파일은 자주 하는 작업의 명령어, 순서, 판단 기준, 실수 목록을 하나의 파일로 정의해두는 방식이다.
- 명령어
- 작업 순서
- 판단 기준
- 자주 하는 실수 목록
스킬 파일의 효과
Section titled “스킬 파일의 효과”반복 입력이 줄어드는 것 외에도 다음 이점을 얻을 수 있다.
- 실수 방지: 판단 기준과 실수 목록을 담아두면 AI가 같은 실수를 반복할 가능성 감소
- 품질 향상: 확인 방법을 함께 제공하여 결과물 품질 향상(“구현해라”보다 “구현하고 이 방식으로 검증해라”가 나은 결과 생성)
도메인별 안내 파일 분리
Section titled “도메인별 안내 파일 분리”이번 프로젝트는 결제, 재고, 주문 등 도메인별로 패키지가 명확히 나뉜 구조였다. 그럼에도 프로젝트의 모든 컨텍스트를 CLAUDE.md 하나에 담아 제공했는데, 이는 결제 도메인 작업을 할 때 재고나 주문 관련 정보까지 함께 로드되는 셈이었다.
AI에게 보여주는 코드 범위가 넓어질수록 다음 문제가 발생한다.
- 컨텍스트 집중도 저하: AI가 현재 작업과 관련 없는 정보까지 함께 로드하면서, 실제로 필요한 정보에 대한 집중도가 떨어짐
- 패턴 일관성 저하: AI가 다양한 도메인의 정보를 함께 참조하면서, 기존 패턴과 어긋난 코드가 나올 가능성이 높아짐
더 나은 방식은 도메인마다 별도의 안내 파일을 두어, 작업 시 해당 파일만 참조하도록 지시하는 방식이다.
payment/PAYMENT.md,stock/STOCK.md처럼 도메인 패키지 안에 별도 파일 구성- 해당 파일에 도메인 구조, 주요 클래스, 비즈니스 규칙, 주의사항 정리
- 작업 시 해당 파일만 참조하도록 지시
볼 코드가 작아질수록 요구되는 컨텍스트가 줄어들어 AI의 품질이 향상으로 이어지게 된다.