Data Structure
Redis는 다양한 자료구조를 지원하며, 각 자료구조의 내부 동작 방식과 시간 복잡도를 이해하는 것은 Redis의 성능을 최적화하는 데 중요하다.
String
Section titled “String”Redis에서 가장 기본적인 자료구조로, key 하나에 value 하나가 대응되는 구조다.
- 문자열뿐만 아니라 이미지, JSON, 직렬화된 객체 등 다양한 데이터 저장 가능
- 메모리 제한: 최대 512MB까지의 문자열 저장 가능
- 명령어
| 명령어 | 기능 | 예시 |
|---|---|---|
INCR / INCRBY / DECR / DECRBY | 숫자 값을 원자적으로 증가 또는 감소 | INCR counter INCRBY counter 5 |
NX 옵션 | 지정한 키가 없을 때만 저장 | SET key2 "value2" NX |
XX 옵션 | 지정한 키가 있을 때만 값 업데이트 | SET key1 "new_value" XX |
MSET | 여러 키의 값을 한 번에 설정 | MSET key1 "value1" key2 "value2" |
MGET | 여러 키의 값을 한 번에 조회 | MGET key1 key2 |
APPEND | 기존 값에 데이터를 추가 | APPEND key1 "suffix" |
GETRANGE | 문자열의 부분을 가져오기 (서브스트링) | GETRANGE key1 0 3 |
SETRANGE | 문자열의 특정 위치부터 값을 설정 | SETRANGE key1 6 "world" |
- 활용 사례: 간단한 캐시 / 세션 관리 / 카운터(예: 방문자 수, 좋아요 수 등) 등
순서를 가지는 문자열 목록으로, 인덱스를 사용해 직접 접근할 수 있다.
- 내부적으로는 연결 리스트(Linked List)로 구현되어 있음
- 메모리 제한: 하나의 리스트에 최대 42억여 개의 아이템 저장 가능
- 기능
| 명령어 | 기능 | 예시 |
|---|---|---|
LPUSH / RPUSH | 리스트의 왼쪽 또는 오른쪽에 아이템 추가 | LPUSH mylist "first" RPUSH mylist "second" |
LPOP / RPOP | 리스트의 왼쪽 또는 오른쪽에서 아이템 제거 | LPOP mylist |
LRANGE | 리스트의 범위를 조회 | LRANGE mylist 0 -1 |
LINSERT | 리스트의 특정 위치에 아이템 삽입 | LINSERT mylist BEFORE "second" "middle" |
LINDEX / LSET | 리스트의 인덱스로 아이템 조회 및 수정 | LINDEX mylist 1 LSET mylist 0 "new_value" |
LTRIM | 리스트의 범위를 잘라내어 저장 (자르기) | LTRIM mylist 0 99 |
BLPOP / BRPOP | 리스트의 왼쪽 또는 오른쪽에서 아이템 블로킹 제거 | BLPOP mylist 0 |
RPUSHX | 리스트가 있을 때만 추가 | RPUSHX mylist "value" |
- 활용 사례: 메시지 큐 / 대기열 관리 / 채팅 로그 저장 / 이벤트 스트리밍 등
- 시간 복잡도
LPUSH/RPUSH/LPOP/RPOP: O(1)- 인덱스나 데이터를 이용한 중간 데이터 조회: O(N)
BLPOP / BRPOP
Section titled “BLPOP / BRPOP”기존 RPOP / LPOP 명령어에 블로킹 기능을 추가한 명령어로, 리스트에 아이템이 추가될 때까지 대기하다가 아이템이 추가되면 해당 아이템을 반환한다.
BLPOP/BRPOPkey [key …] timeout- key: 대상 리스트의 키
- timeout: 블로킹 시간(초)
- 대기 시간 초과 시 nil 반환
- 리스트의 키와 아이템 값 반환
- 동시에 여러 리스트에서 가져올 수 있기 때문에, 가져온 값을 구분하기 위해 리스트의 키를 함께 반환
키 안에 또 다른 필드-값 쌍으로 구성된 데이터를 저장하는 자료구조로, 작은 객체나 테이블 데이터를 저장하는 데 적합하다.
- 적은 수의 필드를 가질 때 ziplist나 listpack이라는 특별한 방식으로 인코딩하여 메모리 사용량을 크게 줄임
- 명령어
| 명령어 | 기능 | 예시 |
|---|---|---|
HSET | 필드-값 쌍 저장 | HSET user:1000 name "John" |
HGET | 필드 값 가져오기 | HGET user:1000 name |
HMSET | 여러 필드-값 쌍 설정 | HMSET user:1001 name "Alice" age 30 |
HDEL | 필드 삭제 | HDEL user:1000 age |
HEXISTS | 필드 존재 여부 확인 | HEXISTS user:1000 name |
HGETALL | 모든 필드-값 쌍 조회 | HGETALL user:1000 |
- 활용 사례: 사용자 프로필 / 상품 정보 저장
순서가 없고, 중복된 데이터를 허용하지 않는 문자열의 집합을 저장하는 자료구조다.
- 내부적으로 해시 테이블(Hash Table)로 구현
- 명령어
| 명령어 | 기능 | 예시 |
|---|---|---|
SADD | 값 추가 | SADD myset "apple" "banana" |
SREM | 값 제거 | SREM myset "apple" |
SINTER | 두 집합의 교집합 | SINTER myset yourset |
SUnion | 두 집합의 합집합 | SUnion myset yourset |
SISMEMBER | 값이 집합에 존재하는지 확인 | SISMEMBER myset "apple" |
SMEMBERS | 집합의 모든 값 조회 | SMEMBERS myset |
- 활용 사례: 태그 저장 / 고유 사용자 저장
Sorted Set
Section titled “Sorted Set”Set과 유사하지만, 각 요소에 점수(score)를 부여해 자동으로 정렬된 상태를 유지하는 자료구조다.
- 내부적으로 해시 테이블과 스킵 리스트(Skip List)로 구현
- 명령어
| 명령어 | 기능 | 예시 |
|---|---|---|
ZADD | 요소와 점수 삽입 | ZADD leaderboard 100 "player1" |
ZRANGE | 인덱스 범위 내 요소 조회 WITHSCORES: 스코어 함께 출력 / REV: 역순 / BYLEX: 사전 순 정렬 / BYSCORES: 스코어 범위로 조회 | ZRANGE leaderboard 0 -1 |
ZREM | 요소 삭제 | ZREM leaderboard "player1" |
ZINCRBY | 점수 값 증가 | ZINCRBY leaderboard 50 "player1" |
ZSCORE | 특정 요소의 점수 조회 | ZSCORE leaderboard "player1" |
ZREVRANGE | 높은 점수 순으로 정렬된 요소 조회 | ZREVRANGE leaderboard 0 -1 |
- 활용 사례: 리더보드 / 순위 계산 / 시간 기반 정렬된 이벤트 저장
- 시간 복잡도
- 특정 데이터: 해시 테이블 구조로 O(1)
- 점수 범위 조회: 스킵 리스트 구조로 O(logN)
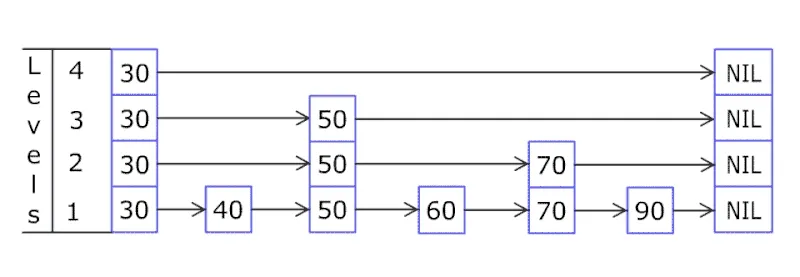
Skip List
Section titled “Skip List”Sorted Set은 Skip List를 사용해 데이터를 관리하기 때문에 O(logN)의 시간복잡도로 데이터를 조회할 수 있다.
- 여러 레벨로 구성된 연결 리스트 구조
- 각 레벨에서 일부 노드만 연결되며, 상위 레벨일수록 노드 수가 적음
- 탐색할 때 최상위 레벨부터 시작하여, 원하는 값보다 큰 값이 나오는 지점에서 하위 레벨로 이동하여 탐색
Bitmaps
Section titled “Bitmaps”별도의 자료구조가 아니라, String 자료구조를 비트(bit) 단위로 조작할 수 있도록 하는 기능의 집합이다.
- 하나의 키에 매우 큰 비트 배열을 저장하고, 각 비트의 인덱스(offset)를 통해
0또는1의 값을 설정하고 조회 - 메모리 제한: 2^32의 비트를 가지고 있는 비트맵 형태
- 명령어
| 명령어 | 기능 | 예시 |
|---|---|---|
SETBIT | 비트 설정 | SETBIT pageviews 1 1 |
GETBIT | 비트 값 조회 | GETBIT pageviews 1 |
BITCOUNT | 비트 값이 1인 비트 개수 세기 | BITCOUNT pageviews |
BITOP | 비트 연산(AND, OR, XOR, NOT) | BITOP AND result key1 key2 |
- 활용 사례: 이벤트 발생 여부 추적 / 월간 사용자 활성화 상태 / 플래그 저장
HyperLogLog
Section titled “HyperLogLog”매우 적은 메모리를 사용하여 집합에 포함된 고유한 원소의 개수(Cardinality)를 추정하는 확률적 자료구조.
- 수 십억 개의 원소에 대해서도 약 0.81%의 표준 오차 내에서 고유 원소 개수를 추정
- 메모리 제한: 최대 12KB 사용 / 최대 2^64개의 원소 저장 가능
- 명령어
| 명령어 | 기능 | 예시 |
|---|---|---|
PFADD | 원소 추가 | PFADD visitors "user1" "user2" |
PFCOUNT | 고유 원소 개수 추정 | PFCOUNT visitors |
PFMERGE | 여러 HyperLogLog 병합 | PFMERGE total_visitors visitors1 visitors2 |
- 활용 사례: 대규모 사용자 방문 기록 / 이벤트 추적
Geospatial
Section titled “Geospatial”지리 공간 데이터(경도, 위도)를 저장하고, 특정 지점 주변의 다른 지점들을 검색하거나 두 지점 간의 거리를 계산하는 데 특화된 기능을 제공한다.
- 내부적으로는 Sorted Set을 활용
- 명령어
| 명령어 | 기능 | 예시 |
|---|---|---|
GEOADD | 좌표 추가 | GEOADD locations 13.361389 38.115556 "Palermo" |
GEOSEARCH | 좌표 조회(반경) | GEOSEARCH locations FROMMEMBER "Palermo" BYRADIUS 100 km |
GEODIST | 두 지점 간 거리 계산 | GEODIST locations "Palermo" "Catania" |
- 활용 사례: 근처 매장 찾기 / 배달 서비스에서의 위치 기반 검색
Stream
Section titled “Stream”Redis Streams는 로그 데이터나 이벤트 스트리밍을 관리할 수 있는 자료구조로, 메시지 브로커로서 기능을 제공한다.
- 특징
- 각 메시지는 고유한 ID와 함께 저장되며, 시간순으로 정렬됨
- 소비자 그룹(consumer group)을 통해 여러 소비자가 데이터를 효율적으로 처리할 수 있음
- 데이터 손실 없이 대규모 메시지 스트리밍 처리 가능
- 이벤트가 발생할 때마다 자동으로 데이터를 추가하고, 필요 시 각 소비자가 처리한 위치를 추적할 수 있음
- 활용 사례: 실시간 로그 수집 / 이벤트 소싱 / 메시지 큐